























在去年的7月份,我们发布了9.0系列的提取算法,它搭载着我们自研的DangoNet3架构,也代表着当时的团子最先进、最高性能的提取架构。
而如今,团子的“排行榜”正在改写!研发周期将近一年、代表着我们目前最先进的架构——DangoNet4架构正式出山!而基于此架构的团子10.0系列算法也在今日正式发布😇
都提升了哪些?我们为那些太长懒得看的用户简单介绍新版本的特性:
- 分离质量相较上代大幅提升56%
- 注意力机制改良,更好的识别乐器和人声,彻底杜绝乐器被当成人声错误删除的问题。
- 人声移除更准确、残留更少。
- 伴奏修复模块(WMIR)更新,乐器更饱满,声音更平滑。
- 缓解因声音过大导致的爆音出现。
- 缓解用户上传MP3等有损压缩歌曲时,提取质量变低的问题。
分离质量大幅提升56%
经过精心的架构改良,本代团子不仅具备了更为强大的识别能力与注意力机制,其参数量——可视为AI的“脑容量”——相较于第九代版本近乎翻倍。此外,我们还额外增加了30%的训练素材,这一系列的“多管齐下”共同促使团子的提取性能实现了惊人的飞跃。特别值得一提的是,在伴奏人声提取算法方面,其SDR(源失真比)相较于第九代有了显著的0.7dB的提升,而要知道第九代相较于第八代的提升仅为0.43dB。正因如此,如今的团子性能已然达到了一个前所未有的高度。
让乐器丢失成为历史
得益于团子的架构改良,团子的AI目前拥有更广阔的“视野”和“注意力”,它可以在一首歌曲里更加理解音乐的构成,举个例子,人声的某些唱歌声音,如长尾音的“啊”,其实在AI的眼中和某些乐器十分相似,比如小提琴或吉他。而小伙伴们可能很迷惑,小提琴是小提琴、吉他是吉他、人声是人声,这有什么“难分辨的”,我听起来完全不同呀🤔
这是因为人类天生有“分析上下文”的能力,人类听歌并不是“一帧一帧”的听,而是连贯的听下去,所以人听到“啊”的声音时,自然能根据记忆中整首歌所发出的声音“一起”认定为这个声音是“人声”而不是某种乐器。实际上,团子早在8代算法中就已经引入了和人脑相似的注意力机制,在9代算法中,我们将“大架构”分离成逐个的“小架构”、让不同模块专注分工做好自己的事情,来获得更强的提取稳定性,其中的“注意力”机制也拆分为单独模块(团子注意力模块),而如果说9代算法的“拆分”是我们的第一次尝试,那么10代就是将其发扬光大,我们大幅度改良了注意力机制,现在它的视野更广阔,更像是人脑一样去分析歌曲的“上下文”内容,从而正确的标记人声和伴奏,即便遇到“听起来像是人声”的声音,团子也会根据上下文去准确的标记它到底属于什么——经过我们的测试,在上一代反馈的仍然乐器被错误当成人声删除的音乐中,在本代中他们全部得到了完整的保留。
更精细,更理解人声
我们向您介绍了团子的全新架构如何不会错误的把乐器当成人声删除,而这只是一个好的提取架构的一部分,人声本身的消除能力也同样重要——当然,全新的架构也大幅度增强了人声消除能力,主要在三个方面得到提升:
- 更准确的移除“和声”:经过我们的测试,我们发现市面上的算法、同样也包括团子的9.0算法,在移除带有和声的片段时,尽管能成功的移除绝大部分人声,但和声部分总会有一些“若隐若现”的残留,这些残留可能乍一听并不明显,但仔细听会发现他们主要分布于低频部分,如果单独把这部分残留“扣”出来去听,会发现他们是类似一种非常低闷的和声,而这部分残留会导致提取出的伴奏低音部分听感非常不自然和不准确。而本代算法中,我们为团子加入了先验知识,让AI能够强化学习乐理中和声的匹配范式。现在,团子可以更准确的移除带有和声的人声片段,并彻底杜绝“若隐若现”的和声残留问题。
- 更准确的移除“小人声”:在前代中,我们发现团子遇到一些原曲中细微的小人声时,经常会无法正确标记并移除他们,本代我们同样解决了这个问题,现在无论人声的大小如何,团子仍然可以游刃有余。
- 更准确的移除长尾音和效果器:得益于我们注意力架构的改良,现在我们的AI视野更广,某些歌曲的人声的尾音非常长,在前代算法中会丢失上下文内容导致人声的尾音无法被正确移除,而本代算法则可以有效的删除歌曲中任意的人声。同时,我们加入了更大的抗效果器学习,在前代中,我们即便移除了主人声,但效果器的残留依旧明显,如仍然有一些“混浊”的人声混响残留在伴奏中。现在团子的算法可以更准确的移除那些带有厚重效果器的人声了。经过我们的测试,在现代音质中,10代的提取出的伴奏普遍要比9代干净。
四个音频从上至下分别是:原曲、9.0算法提取结果、10.0算法提取结果、10.0算法提取的人声。
这首歌取自林俊杰的《美人鱼》的某个现场版,在原曲中,人声非常的小(并且混响非常的大),可以听到,在9.0中团子无法正确的移除此内容,因为该人声尽管在人类听起来“确实是个人声”,但对AI来说它过于“扭曲”以至于无法正常识别,而在10.0中,即便如此“刁钻”人声,团子也可以正确的移除。
听感依然重要
团子除了拥有强悍的提取能力外,还有一个特色的独家本领,也就是我们的 WMIR 模块,它不是用来“提取”或“删除”内容,而是用来“恢复”内容,在市面其他算法还在解决“如何删除人声”时,团子已经进入了下一个时代——如何让伴奏听起来更饱满、更响脆。
在本代,我们的WMIR架构再次大幅度改进,它输出的内容更符合让人类满意的听觉——在学术上我们称之为“心理声学”,团子会寻找歌曲中不自然的地方——如微弱的滋滋杂音、伴奏突然发闷瞬态破坏等区域,并自动修复或弥补这些缺陷,尽管我们的WMIR架构并不会获得学术上更高的SDR分数,因为我们WMIR架构主要目的是“修补”来获得更好的听感,而不是预测正确的相位——所以它在“学术指标”上来看可能性能并不好,但在我们的双盲测试中,带有WMIR架构的团子输出,在普遍上获得更多听众们的满意。
另外,本代中我们进一步的优化了因为人声部分发音(如齿音)过大、导致移除人声后剩下的伴奏带有听起来声音“缺陷”、音量“恍惚”的问题,它的听感相比上一代更加自然和平滑,声像也更加饱满立体。

抗干扰,任何情况游刃有余
团子开通了反馈通道后,我们收到了大量用户的反馈,而在“听感不好”的反馈中,主要出现两种问题:
- 歌曲中人声过大导致“爆音”,当声音被记录到数字文件中时,过大的声音因为超出记录范围无法记录而被“剪裁”,这会导致出现“削波”问题,它听起来类似于原本的声音变得失真,并且伴随各种“噼里啪啦”的爆音。而很多现代音乐为了增大音量来吸引听众,经常会出现“爆音”问题,这些爆音在原曲中可能因为伴奏或者人声的掩盖,听众无法听出来,而团子在删除人声后,这些爆音就会很突兀的显露出来,导致听起来正常的伴奏中莫名其妙带有“咔哒”声音或者“噼里啪啦”声音,本代算法中我们增加了抗爆音的训练,经过测试它可以有效缓解这种爆音问题,不过还需注意的是,尽管它能缓解一部分爆音,但如果爆音过为严重的话,您可能还需要在本地自行使用类似iZotope RX之类的软件去修复它们。
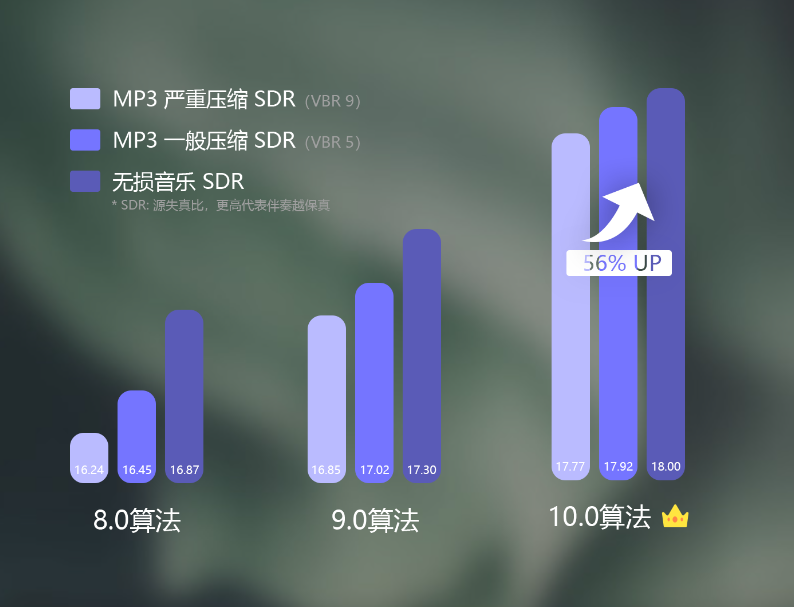
- 用户上传MP3等有损压缩文件,导致分离音质变差,或出现意外的杂音、滋滋声等问题。团子一直希望用户上传无损音乐,因为有损音乐会为了缩小音乐文件体积从而删除音乐中某些“人耳听不见”的内容,但实际上这些内容可以辅助团子进行更好的提取和分离,我们想象成歌曲中的人声是张图片,而有损压缩后的人声则变成了模糊且扭曲的图片,这显然会降低AI的识别能力。而本代中,我们添加了压缩算法的先验知识,做到让AI即便遇到被破坏、扭曲的声音也可以尝试识别并提取其中的内容。通过我们实验表明,经过强化学习后我们的算法可以在MP3一般压缩(VBR等级5)甚至是极限压缩(VBR等级9)中,仍然可以保持极高的SDR值,这代表着我们10.0系列的算法可以做到即便严重压缩干扰情况下仍能正确的提取伴奏人声的能力。
那么……接下来呢?
由于本代研发周期过长,为了尽快与小伙伴们见面,我们并没有将“伴奏人声提取”、“更好人声分离”和“和声保留”三个算法一同上线,而是首先发布“伴奏人声提取”功能,在接下来的时间内我们会开始训练更好人声分离以及和声保留算法。

