






















任意乐器分离作为团子重要的在线AI工具之一,在去年5月份上线后获得大量用户好评,我们将分离人声乐器的算法拓展到各式各样的乐器上并让创作者们自由的分离它们,在今年的4月份我们再次的添加了萨克斯、笛子和提琴的提取能力,让团子的分离能力更进一步。
而在几个月前,我们成功研发出全新的分离架构DangoNet3后,我们将其应用到了伴奏人声提取算法上并显著的提升了分离质量,是时候“反哺”了!我们使用最新的架构对任意乐器分离的提取能力进行升级,在最终的测试中全部都相较之前的算法普遍提升了10%-50%提取能力(量化目标:SDR,源失真比)。
在本次更新中,我们升级了6个乐器提取能力,以下是每个提取能力的报告:
电吉他(提升25%)
电吉他作为团子最早上线的提取能力,一直处于“一代算法”,类似于团子伴奏提取5.0的能力,尽管上线时团子的提取能力非常惊艳,但对于即将2024年的现在来说,它的性能和听感已经严重“不足”了,本次升级的电吉他作为我们的“压轴菜”之一,我们额外的筹备了3倍的训练素材,前代我们获得了4.66dB的性能指标,而本代,我们已训练完毕的最终模型是5.82dB,相当于提升了25%的性能,这个性能提升令我们非常满意,训练素材是提升的一部分,而我们的算法在本次也“立了大功”,电吉他目前仍是1代模型,它的性能放在今日已经不足,前代电吉他经常出现四个问题:
- 严重伪影:吉他总是包含了高频的滋滋声,听起来非常刺耳但又不是吉他本身的声音,这是一代算法所限导致的
- 泄露问题:电吉他中总会隐隐约约听到其他乐器的声音,甚至是人声。
- 区分问题:电吉他仍然和部分木吉他混淆,容易提取出错误的音轨。
- 高频丢失:电吉他只能提取到7.5khz,高频丢失,因为算法的“惰性”导致电吉他并不提取高频
针对上面的三种情况,团子得到了新模型的定制改善目标,首先伪影的问题我们全新的DangoNet3本身就是拥有独家的“0伪影输出”模块,实际上训练后最终的输出也的确如此;泄露问题和区分问题因为我们大量“堆料”,引入了更多训练素材,让电吉他更能理解“什么是电吉他”以及“什么不是电吉他”,也得到了大量的改善,尤其介绍的是区分问题,我们将前代的素材以及本次的素材进行了非常耗时的重新整理,诸如类似Clear Guitar这种“很轻”的音色——听起来像是木吉他但实际上是轻微效果器的插电吉他,在前代中我们将其归类为“木吉他”,而本代我们将其归类为“电吉他”,相当于我们缩小了“木吉他”的音色范围,使其只提取最标准的纯净木吉他声音,同时扩大了“电吉他”的音色范围,在前代中我们对这些音色含糊处理,导致可能会让一些意外的其他音色泄露(甚至是琵琶),本代中我们定义了木吉他和电吉他的“边界”。同时,我们将一种特殊的电吉他排除到我们的电吉他模型,它一般称为“Bass Guitar”,相当于插电的“低音贝斯”,本身也能发出吉他的声音,但非常沉闷而且一般是当做“低音贝斯”而不是“吉他”,在前代中我们发现引入Bass Guitar会导致模型有时候错误的将一些Bass也提取出来,从而让剩下的伴奏“缺少低音”,本代我们也经过了重定义并得到了改善。
最后,高频问题我们也得到解决,现在的电吉他不会听起来“闷闷的”,而且非常清晰。
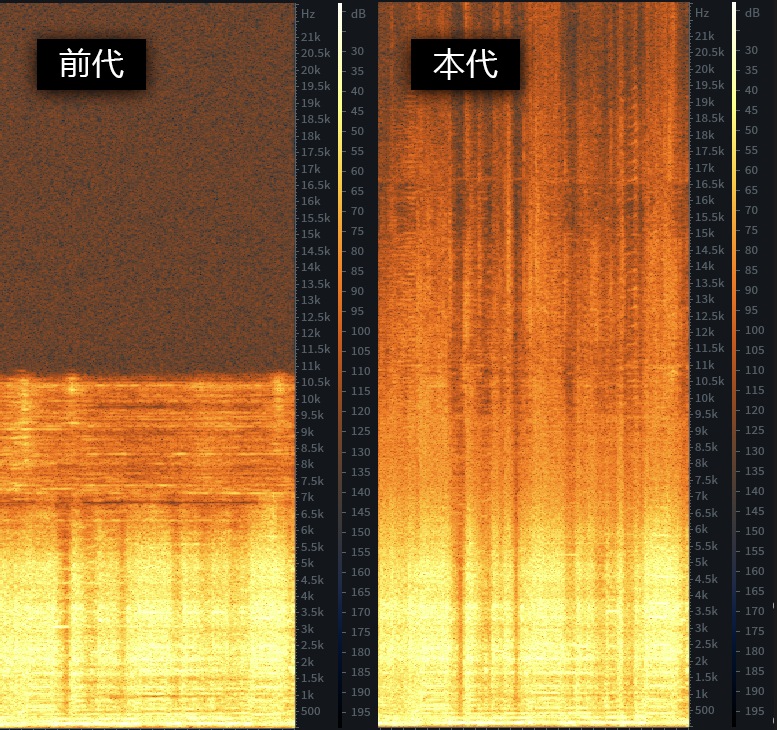
我们还和Demucs4的6轨模型中的“吉他”模型进行对比,由于Demucs的吉他模型是统一提取出“电吉他+木吉他”,而无法单独提取出某种吉他,所以为了方便对比,我们选取了只有“电吉他”歌曲进行对比
原曲:
Demucs4吉他模型(提取困难):
团子1.0老版本模型(发闷,泄露,有杂音):
团子3.0新模型:
可以听到,团子的新模型相比Demucs模型提取能力更强,我们能在嘈杂的歌曲中提取出几乎听不到的电吉他元素,并且提取质量非常清晰,而Demucs只能提取出“虚无缥缈”的一些声音。而纵向对比团子的前代1.0算法,我们新的模型高频更清晰、音色更纯净,没有其他音轨的泄露声音。
木吉他(提升315%)
同样和电吉他相同,木吉他也是“1代算法”,本次我们直接跨级升级到3代算法,木吉他算法在1代中训练的我们深知“并不好”,但当时的训练条件和素材都极其有限,训练出的SDR分数仅为1.82dB,而本次我们获得了5.74dB的“恐怖”成绩,相当于提升了315%的性能,以至于我们都觉得太假重复测试了很多次确定了这个成绩(扶额)。
而木吉他提升甚至超过了100%,归功于我们进行大量针对性的优化,我们在1.0的木吉他中发现了几个问题:
- 识别困难:在大部分木吉他声音较小的歌曲中,根本无法识别其中微弱的木吉他声音
- 严重模糊:提取出的“产物”发糊并且无法识别到音色,听起来像是木吉他但实际上仔细听又觉得“很怪”
- 乐器混淆:非常容易和鼓组的镲/钹音色混淆(就是“洞次打次”中的“次”这个声音),并且非常容易和钢琴混淆,经常把原曲的钢琴+鼓组当成某种木吉他提取。
针对以上情况,我们进行了木吉他专项的优化,我们三代算法首先本身“分辨率”就很高,很容易在复杂的歌曲中提取出定向的内容,而模糊和混淆的问题来自于AI的“幻觉”问题,AI认为这里可能有乐器,但又不太敢承认,所以有一种“想要提取又不太敢提取太多”,最后听起来结果含糊不清,要解决这个问题,算法很重要,而训练素材同样重要,本次我们加入了原有一倍多的训练素材,让AI更能清晰分辨“什么是木吉他”,同样的,我们加入了大量鼓组和钢琴的对抗样本来让AI理解“这些声音不是电吉他”,经过大量的研发和调试,我们的第三代木吉他模型非常清晰,且杜绝了模糊和混淆问题,以下为我们测试时的一个音频案例,同样的我们也引入了最新的Demucs4进行对比,由于Demucs的吉他模型是统一提取出“电吉他+木吉他”,而无法单独提取出某种吉他,所以为了方便对比,我们选取了只有“木吉他”歌曲进行对比:
原曲:
团子1.0老版本模型(模糊不清):
Demucs4吉他模型(比较模糊,有提琴声音泄露):
团子3.0新模型:
可以听到,我们的1.0版本的模型提取非常困难,听起来非常模糊且“空洞”,而Demucs4得到改善,但仍然无法提取出木吉他灵魂的“扫弦”声音(也就是很清爽的“咔嚓咔嚓”声音),并且原曲的弦乐器也有一部分泄露,而团子的全新3.0版本模型得到了大幅度的改善,提取的木吉他干净、清晰且响脆。
钢琴(提升8%)
钢琴一般在8khz以下内容丰富,我们独特的为了钢琴训练了一个特殊的模型,让AI更加关注钢琴出现的频率范围,这显著的提升了钢琴的性能。
前代中,我们钢琴得到的SDR为3.81dB,而本代我们得到了4.13dB的分数,由于时间原因我们未能在钢琴里添加新的素材(预计下一代会着重升级钢琴性能),但因为团子的DangoNet3架构,使得即便素材不变的情况下,仍然将模型提升了8%的性能,新一代的钢琴更加清晰、残留显著变得更少。同样的,我们和前代算法以及Demcs4进行对比:
原曲:
团子2.0老版本模型(发闷、不清晰):
Demucs4钢琴模型(完全无法提取):
团子3.0新模型:
可以听到,相比2代算法,钢琴的3代算法提取的更加精细和清晰,没有发闷发糊的感觉,而Demucs由于是个“研究学习模型”,而并非像团子这样实打实使用的工业模型,它训练钢琴和吉他时使用的是电脑合成的MIDI素材而非真实世界里乐器和歌曲的声音,所以更像是个“学术圈”的玩具,而并不能理解该歌曲中的钢琴元素,导致识别失败并提取出非常奇怪的合成器声。
提琴(提升16%)
前代SDR为4.03dB,而本代我们提升至4.68dB,相当于提升了16%的音质,在我们的前代模型反馈中,提琴经常会和“电吉他”混淆,本代我们同样和笛子相同加入了大量的电吉他对抗样本,经过实验性能得到提升并且混淆问题也得到改善,同时,我们对提琴引入了特别的训练,部分歌曲的String音色可能音量较轻,导致模型难以识别和提取,本代我们让AI去学习了大量“小声音”,这对一些嘈杂的歌曲中提取提琴有所帮助。最后,我们对提琴的拟合能力进行了调整,现在提琴能更加“大胆”的从音乐里识别出对应的音色并提取,而前代可能对一些含糊的声音不会去提取。
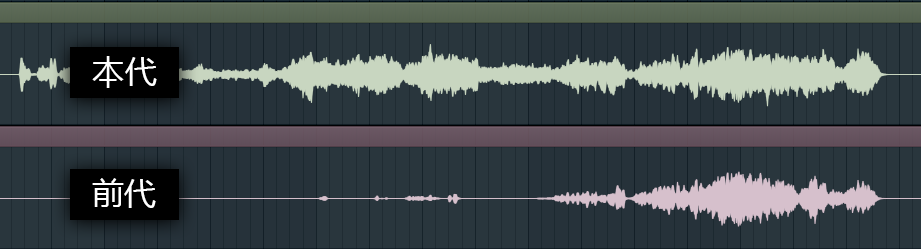
原曲:
团子2.0老版本模型(乐器丢失):
团子3.0新模型:
可以听到,在2.0模型中,部分弦乐器丢失,而在3.0中我们加强训练后,可以捕捉到连贯且细小的弦乐器声音。
管乐器及萨克斯(提升40%)
在上一代模型中我们得大量反馈,在消除了歌曲中的管乐器或者萨克斯后,剩下的“伴奏”中仍然有一些听起来“刺刺”的锯齿声音,根据我们得到的反馈发现,这种声音出现因为两种问题:
- 管乐器或萨克斯天然包含“气流”声音,而仅仅删除乐器声、不删除气流声的话,会导致气流声仍然在伴奏里并听起来很“不协调”。
- 模型本身对高频提取能力较差,管乐器和萨克斯同样遵守“低频高能、高频低能”的频谱样式,而模型本身为了“偷懒”仅仅提取了中低频的乐器声音,高频中仍有轻微残留,这对模型来说“这么点残留可有可无”,但实际上在某些情况下(如安静的歌曲中)仍然能听到这种高频残留,听起来像是“锯齿”一样的声音。
针对以上两种情况,我们特别的为萨克斯定制了只属于它自己的模型规则——强制删除气流声,以及增加高频的提取权重,经过紧张的训练和调试后,我们的新模型以6.32dB的分数训练完成——而前代仅有4.51dB,这相当于提升了40%的性能。在我们三代算法的训练中,对不同的乐器使用不同的方案,而不是以前的“千篇一律”,这实际上确实有效果,这也给予我们未来研发很大的灵感。

原曲:
团子2.0老版本模型(提琴泄露):
团子3.0新模型:
作为和“弦乐器”搭配的老搭档,管乐器经常和弦乐器一起出现,而二者在频谱上较为相似使得AI分离他们困难,该歌曲的弦乐器在二代算法中被错误识别成萨克斯而被消除,而经过强化学习的三代算法得到了改善。
笛子(提升35%)
前代我们得到的SDR指标为4.43dB,而本代我们得到了6.00dB的指标,量化来说相当于提升了35%的音质,和萨克斯提升了40%的研发路径不同,萨克斯是因为我们新的算法从而得到了非常巨量的性能提升,而新的笛子的提升原因,主要是因为我们引入了非常多的“对抗训练”,前代中我们的笛子容易和一些乐器“打架”,错误的认为某些乐器也是笛子,从而错误的提取或删除它们,而本代我们加入了大量的“对抗训练”,让AI能理解更多“什么声音不是笛子”,减少错误的提取能力,实际上我们的工程师试听时也能明显发现笛子和提琴、吉他、人声“打架”的问题得到非常良好的改善,目前笛子提取出来的声音非常纯净,而且支持提取笛子独特的"气流声",不会有其他音轨的泄露问题。
除此之外,我们还更新了一个“木吉他·激进”模型,我们让该模型失去一些“严谨”,并增加一些“灵活”来让该模型可以在音乐中尝试找到更多木吉他的声音,该模型提取出的木吉他会更多、更清晰,但可能不会“准确”且可能有一定的轻微残留,该模型为实验模型,您可以在上传选择模型时勾选“显示全部模型”选项来使用。
我们还优化了整体分离的架构,使用三代算法提取时,不但性能得到大幅度提升,提取的速度也进行了相应的优化甚至要比二代或一代更快。
至此团子的第三代任意乐器分离的全部内容已经更新完毕,我们筹备了数据大半年之久、训练也耗费了三个月左右的时间,而新版本的各个模型的质量也符合甚至超出了我们的期待,我们可以称之为“次世代”。希望这些提取能力能给你带来足够的惊喜😇😇
您可以随时联系我们并提供建议和反馈,在未来我们仍会持续的添加新的提取能力以及更新现有的提取能力,敬请期待!

