




















整个10月份“咻”的就过去了👻上个月的研发日志我们提到,接下来我们会重新将精力分配到“音频音质修复”模块。本月我们将解禁研发结果~
先说结论:有戏!👻👻
10月份我们共计做了312场试验,产生了明显的突破,我们之前的实验介绍过,有损音频的恢复可以分为两个过程:包络的恢复和“纹理”的恢复,包络可以理解为音频频谱的“底噪”,也就是每个乐器的“形状”,它是简单易学的,甚至不需要深度学习,一些普通的算法也能通过统计来根据低频恢复出有意义的高频包络。但包络只是需要恢复的一部分,而“纹理”更为重要,比如很多带谐波乐器的“谐波”,比如很多合成器乐器的“线条”,为了更好理解,我们称呼其为“纹理”。
想象一张“楼房”的照片,包络就是楼房的“竖直长方形”的大体形状,而纹理就是楼房上面的砖块、窗户的纹理,从神经网络的角度来说,包络属于是比较好学习的“低频信息”,而纹理属于很难学的高频信息,这里就出现了有趣的事情,我们修复的目标本身就是频谱(团子在频谱方面去做修复而不是纯波形或像是demucs那种混合domain👻),频谱本身就是波形的STFT转换物,它本身就包含了低频高频信息,而幅度谱比作为“图片”的话,它的低频和高频就是我们所谓的包络和纹理,我们之前就是“卡”在了网络智能恢复包络和简单的纹理,但无法恢复复杂的高频纹理信息,但我们在本月的实验中已经成功突破了此问题,现在网络也能修复出可观稳健的纹理信息了。
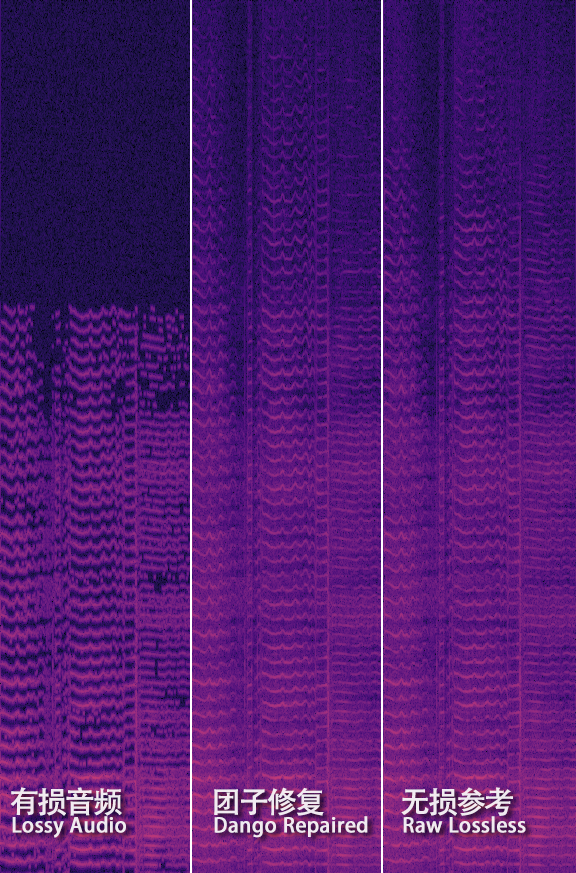
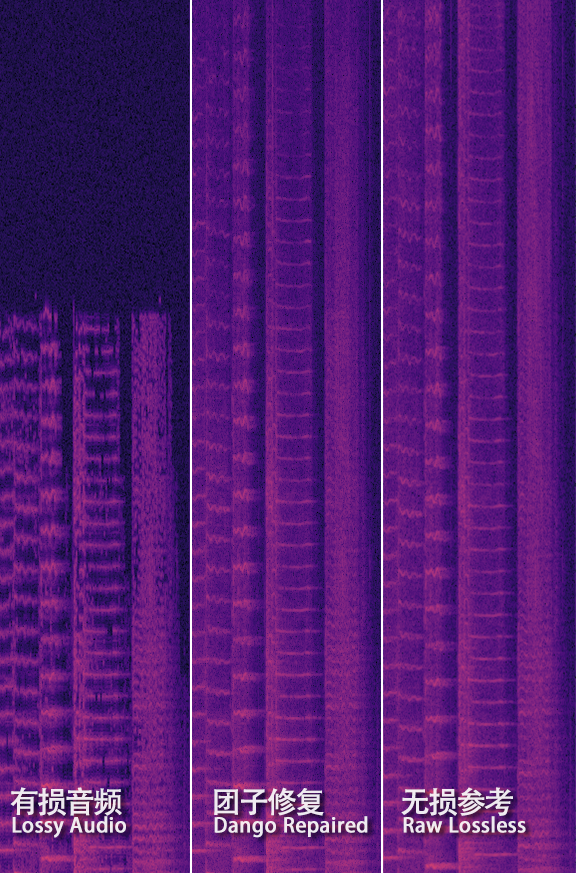
我们释放了两个示例图,可以看到,和之前相比,团子可以生成出非常有意义的高频,这是前所未有的,据我们所知,目前市面上以及学术界都暂时无法达到我们的修复水平,这是重大突破,也标志着我们可以沿着这条路线研发下去👻👻
当然,生成可靠纹理只是困难的一部分,首先在上面的示例图可以看到,部分区域的纹理生成仍然不尽人意,但这只是我们使用小规模的数据集进行训练的,一旦确认可靠,我们将使用更大的模型和更多的数据来训练。其次,和类似的音频超分辨率(Audio Super Resolution)不同,有损恢复是更为复杂的情况,超分辨率只考虑从剪切(cutoff)处向更高的频率进行拓展,但有损编码器不仅仅是剪裁高频内容,还同时会损伤中低频内容,产生伪影或一些明显的频谱可见的“孔洞”,这些损伤和孔洞会根据不同歌曲、不同编码器甚至是编码器的不同参数而不同,也就是网络不但要补全高频的频谱,还要修复中低频的信息,同时还不能产生任何伪影或听觉的异变,这仍然是个非常大的挑战,但这些相对来说都是可以想办法解决的👻👻团子在音频AI方面耕耘许久,早已经积累了丰富的研发经验,我们相信全网首发的音频修复功能的到来就在不远👻👻
总结,我们在小规模的实验中产生了突破,而小规模的实验转换为大规模的训练(和所需要的高质量训练素材)、还有诸如上文所述的低中高频修复等问题仍需解决,可能仍然需要较长时间来完成整个功能的研发,我们预计在12月初公布具体的时间安排(锅先扔给下个月.jpg)
另外,有一些小伙伴向我们进行了一个“奇怪”的反馈,某些网站标注了自己的产品拥有多少数量的“SDR”,并尝试和团子进行对比。
我们在很多产品介绍场景下提到过该词,简单来说SDR是一个科学评估指标,大概是讲生成的内容和原始内容的“相似程度”,更高的SDR代表更接近原始音频、也就是客观上的“更好”。
你可能在网上见过一些伴奏提取网站,宣传自己“SDR 得分高达 XXX”(有的甚至标注到24+的SDR分数🤣)。这个 SDR 就像是音源分离的“考试分数”,分数越高,通常说明它从歌曲中分离人声和伴奏的能力越强,但这里有一个关键陷阱:这个“分数”高低,完全取决于它参加的是哪场“考试”——也就是用了什么数据集。不同的数据集就像不同的考卷,有的考题简单,有的极难。一个工具在简单的试卷上可能轻松拿到 95 分,而在高难度试卷上或许只能得 70 分;类比到“考试”的数据集,有的数据集可能专注于古典音乐、有的专注于电子音乐。
所以,当两个网站各自吹嘘自己的 SDR 分数时,如果它们背后使用的测试歌曲和测试音轨根本不同,那这两个分数就像是一个人在跑马拉松,另一个人在下围棋,然后比较谁“做饭能力比较强”一样抽象🤣
目前业内常用 musdb18 这个开源数据集,以others轨道为例,10-12分已经是相当优秀的成绩。也有一些平台使用自建数据集(如MVSEP),在这些数据集上 14-18分同样十分优秀。
团子所有提及的 SDR,均基于我们的内部数据集测试,我们内部数据集包含了大量不同曲风、语言甚至效果(如压缩、录制场景等)。 正因为标准不同,我们从不直接与其他平台对比分数,而是只和我们自己的前一代模型比较——因为用的是同一套题,所以“成绩提升了百分之多少”这个说法是真实、严谨的。
另外,给大家一个直观的参考:24分以上的SDR是一个极其夸张的概念。类比一下,如果用SDR去衡量一首192/320kbps的高品质MP3和无损音频的区别,它们的SDR分数也就在23~25分左右。这已经达到了人耳极难分辨的级别——人耳很难区分出高品质MP3和无损音频的区别,可以下定论的说,24分的SDR在人耳里除非做过专业训练,否则根本听不出区别。以音质为主的团子,也绝不敢如此“吹嘘”🤣
因此,下次再看到各种华丽的SDR分数,请大家多留个心眼:这个数字本身可能是真的,但它未必能代表对你手中歌曲的处理效果。技术的好坏,最终还是要你用耳朵来验收,听一听分离后的声音是否干净、无损,那才是最真实的评判。

